Building a Production-Grade AI Identity Verification System — MedScribe AI
Full implementation walkthrough of a healthcare KYC/KYP verification module: AI confidence scoring, human-in-the-loop review, state machines, optimistic locking, GDPR compliance, and a clear path to production scale. Built with FastAPI + React + PostgreSQL.
This is a real project breakdown. MedScribe AI is a healthcare transcription platform with a fully isolated identity verification module built to KYC/KYP (Know Your Patient / Know Your Provider) standards. This article walks through every architectural decision — why it was made, what the tradeoffs were, and how it maps to production healthcare systems.
What the System Does
The verification module lets a user submit identity documents (passport, national ID, driver's license, medical certificates) for review. An AI pipeline scores each document automatically. A human admin makes the final approval or rejection decision.
User submits docs → AI scores confidence → Admin reviews → Approved / Rejected
(88% confidence) (View file, decide)The AI never makes the final decision. It only provides a confidence signal. This is a deliberate human-in-the-loop design — required under the EU AI Act Article 14 for high-risk AI systems in healthcare.
Screenshots
Submit Verification Form
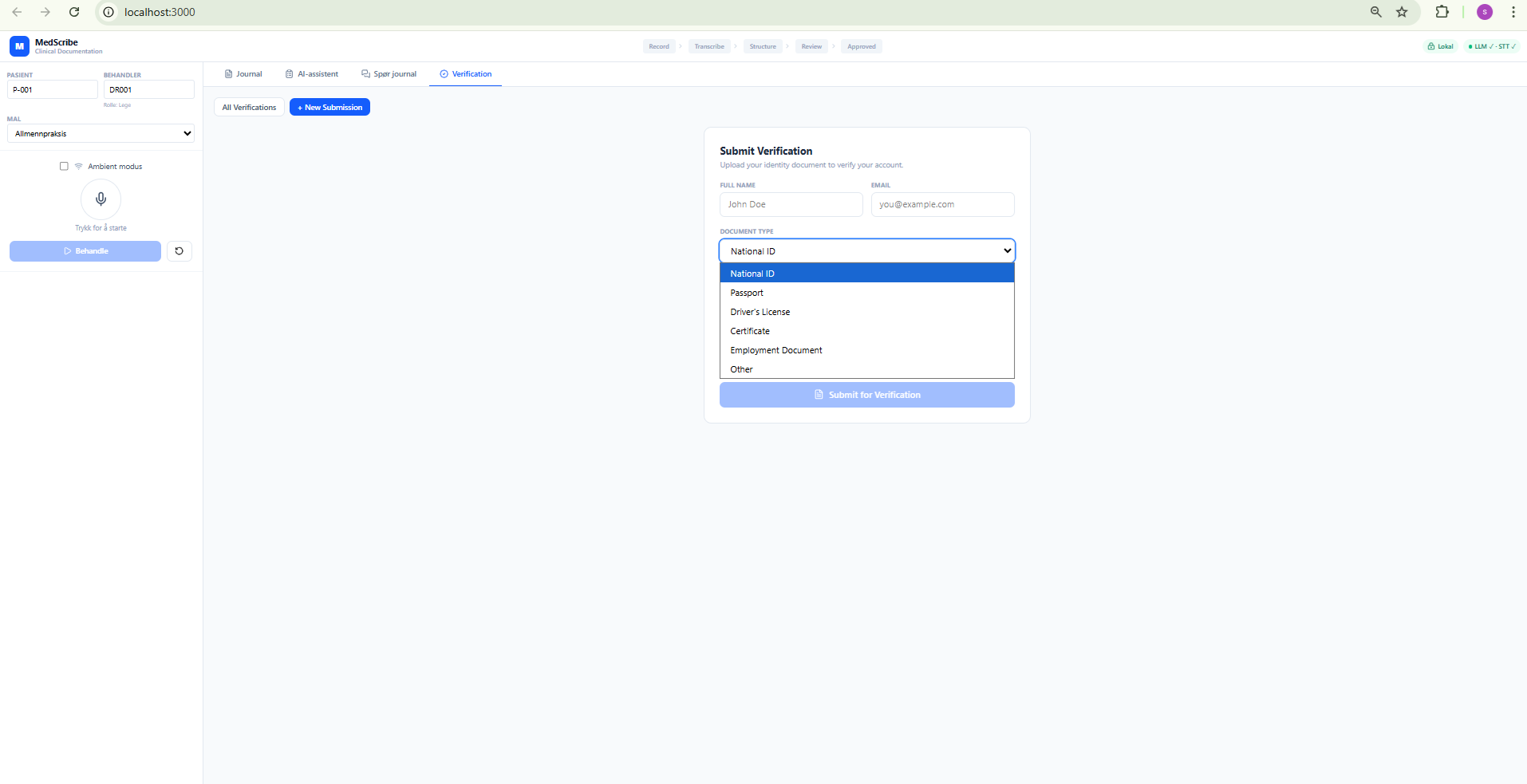
Drag & drop document upload with document type selection. The button shows "Connecting..." until JWT authentication resolves — solving the auth race condition described later.
Admin List View
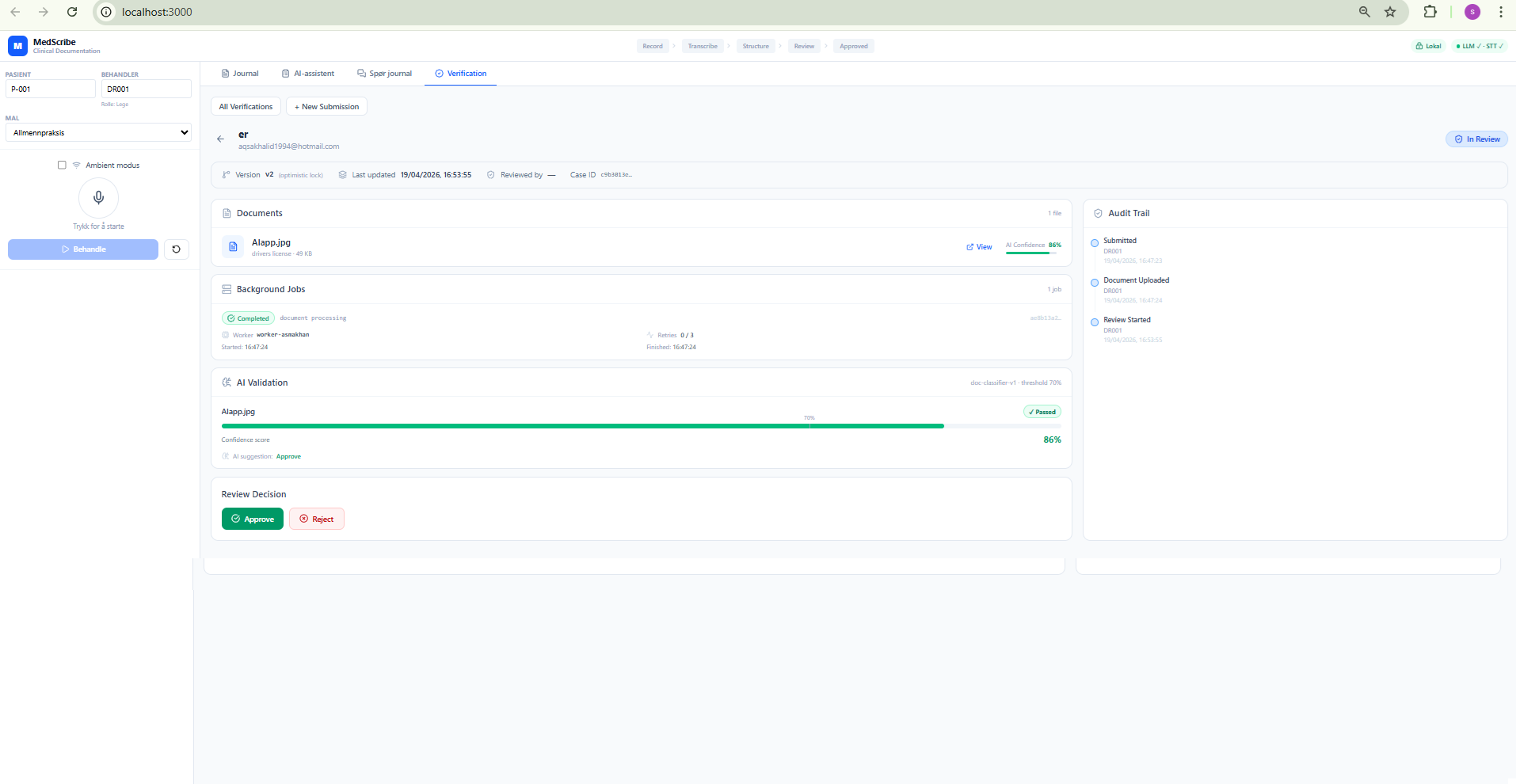
Status summary cards (Pending / In Review / Approved / Rejected), filterable table, reviewer column. Admins see all cases; regular users see only their own.
Detail View — Pending Case
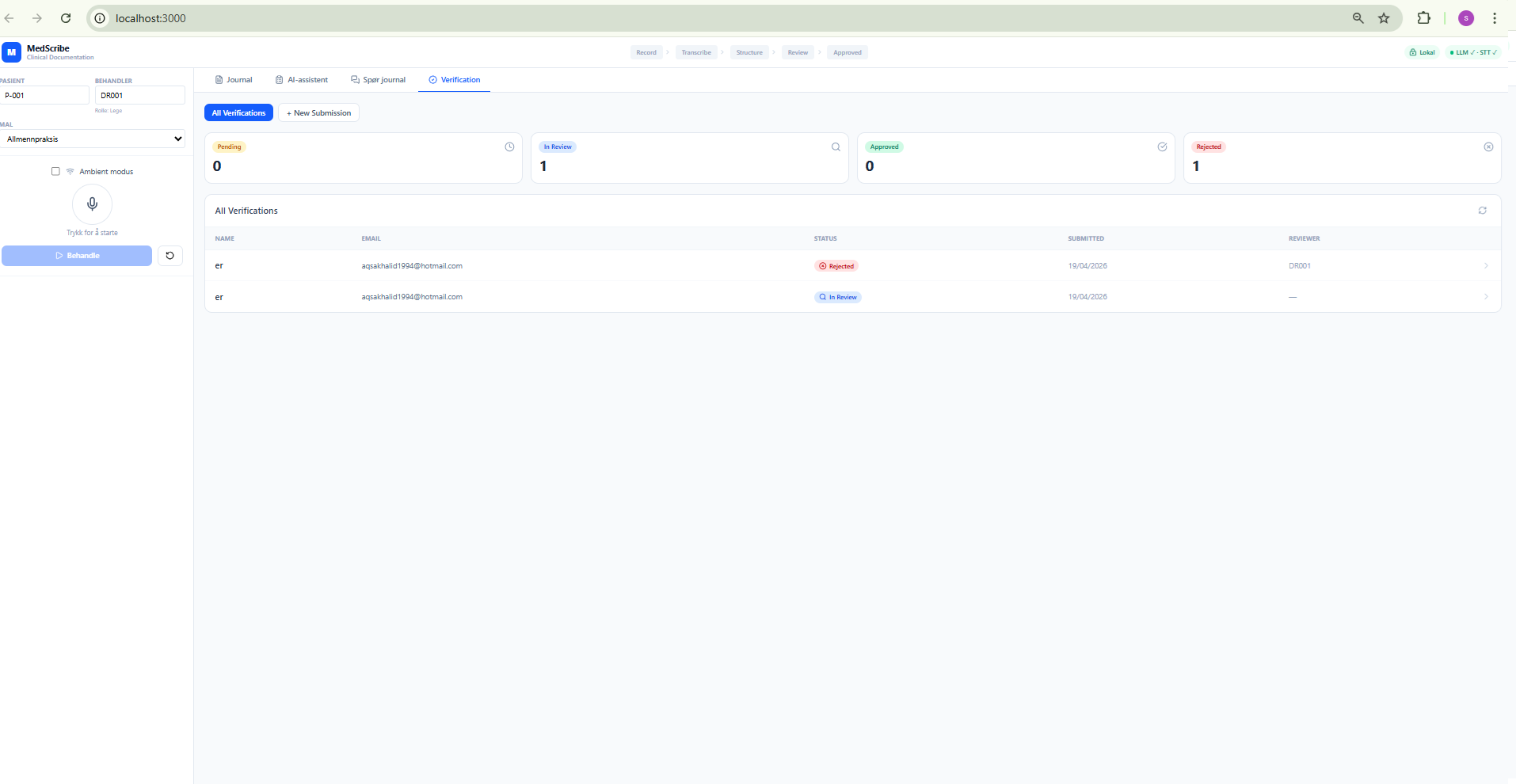
Shows: version number (optimistic lock counter), Background Jobs panel (worker ID, retry count, timestamps), AI Validation panel (confidence bar with 70% threshold marker), and the Review Decision panel for admins.
Detail View — Rejected Case
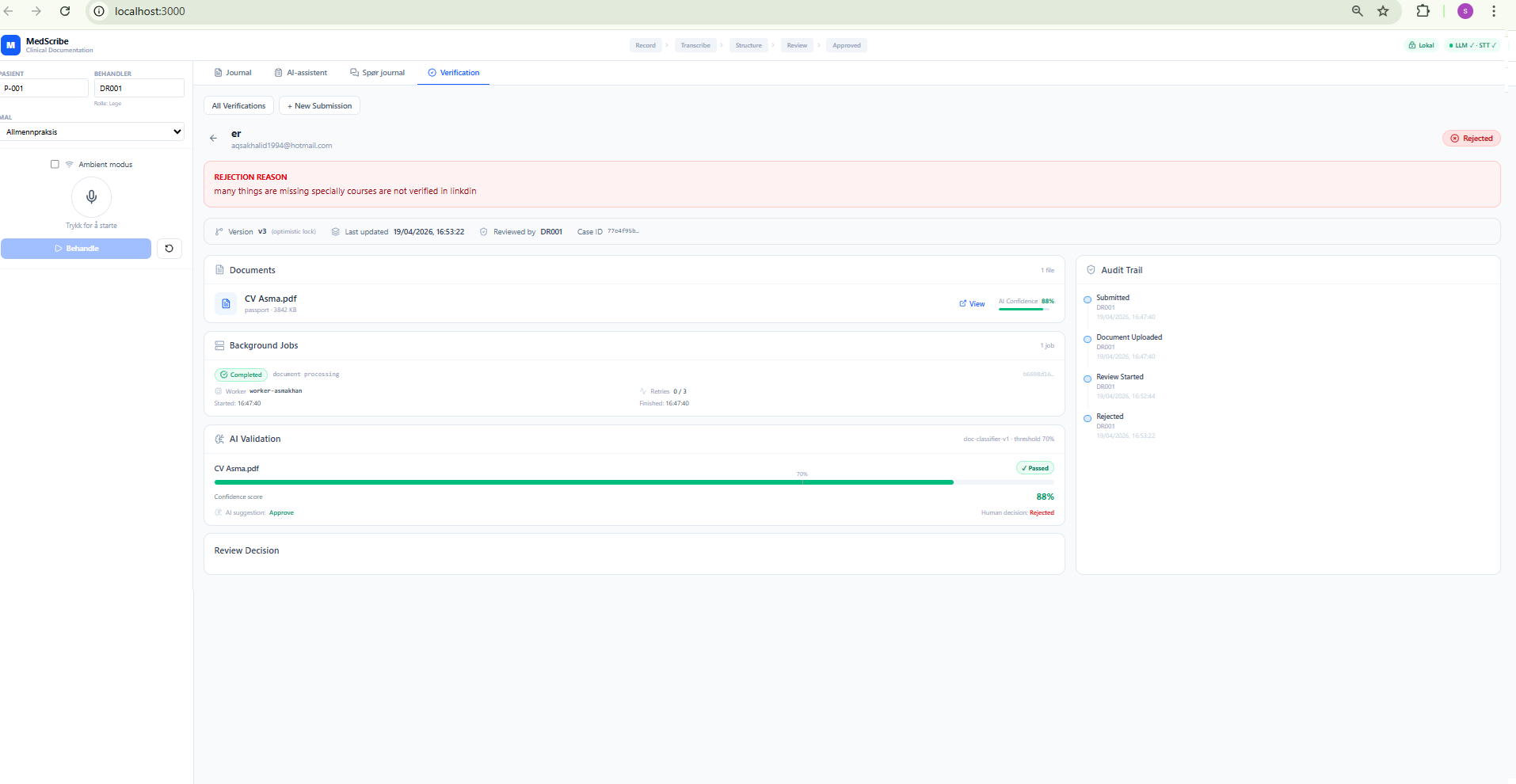
Rejection reason banner, full audit trail timeline, and the critical line: AI suggestion: Approve / Human decision: Rejected. The system records every AI-human divergence.
Tech Stack
Backend
| Layer | Technology | Reason |
|-------|-----------|--------|
| API | FastAPI (Python 3.11+) | Async, OpenAPI-first, native Pydantic validation |
| ORM | SQLAlchemy 2.0 async | Async sessions, repository pattern, vendor-agnostic |
| Dev DB | SQLite via aiosqlite | Zero-config local dev, same schema as prod |
| Prod DB | PostgreSQL | ACID, concurrent writes, partitioning for audit log |
| Auth | JWT (HS256) via python-jose | Stateless, RBAC via role claim |
| File storage | Local filesystem (swappable) | storage.py abstraction — swap to Azure Blob / S3 via config |
| Background jobs | In-process asyncio | Production: Celery + Redis |
| Settings | pydantic-settings | Type-safe env vars, fail-fast validation |
| Logging | structlog | Structured JSON logs, machine-parseable |
Frontend
| Layer | Technology | Reason |
|-------|-----------|--------|
| Framework | React 18 + TypeScript | Typed components, Vite dev server |
| Styling | Tailwind CSS v4 | Utility-first design tokens |
| Build | Vite | HMR, ESM proxy to FastAPI backend |
| API client | Typed fetch wrappers | No axios dependency, matches backend schemas exactly |
Module Structure
src/medscribe/verification/
├── enums.py # VerificationStatus, DocumentType, VerificationAction
├── models.py # Domain models (Pydantic) — pure Python, no DB imports
├── repository.py # Data access — 4 repository classes, pure DB I/O
├── service.py # All business logic — state machine, locking, AI simulation
├── security.py # File validation — MIME allowlist, 10 MB limit
├── storage.py # File I/O abstraction — swappable to cloud
└── __init__.py
src/medscribe/api/
└── verification_routes.py # 10 REST endpoints
frontend/src/verification/
├── types.ts # TypeScript interfaces matching backend schemas exactly
├── api.ts # Typed fetch wrappers
├── VerificationUpload.tsx # Submit form
├── VerificationList.tsx # Admin/user list
└── VerificationDetail.tsx # Detail view with all panelsAPI Endpoints
| Method | Path | Auth | Description |
|--------|------|------|-------------|
| POST | /api/v1/verification/ | Any | Submit new case |
| POST | /api/v1/verification/{id}/documents | Owner | Upload document |
| GET | /api/v1/verification/ | Any | List own verifications |
| GET | /api/v1/verification/{id} | Any | Get detail + docs + jobs |
| GET | /api/v1/verification/{id}/documents/{doc_id}/download | Any | View/download file |
| GET | /api/v1/verification/{id}/audit | Any | Full audit trail |
| POST | /api/v1/verification/{id}/resubmit | Owner | Resubmit after rejection |
| GET | /api/v1/verification/admin/all | admin | All cases |
| PUT | /api/v1/verification/admin/{id}/review | admin | Start review / approve / reject |
Architecture Deep Dive
1. Domain Isolation (Bounded Context)
The verification module is built as a completely separate domain from the clinical module. It has its own enums, models, repositories, service, and routes. No file inside verification/ imports anything from the clinical domain.
This maps directly to Domain-Driven Design (DDD) bounded contexts:
- Clinical workflows (visits, transcripts, notes) evolve on a different cycle than identity verification
- A bug in verification cannot crash the clinical pipeline
- The module can be extracted into its own microservice later — you only change the transport layer
The cost: intentional duplication. VerificationAuditEntry and the clinical AuditEntry are structurally similar but deliberately separate. A shared audit model creates hidden coupling that causes breaking changes when either domain evolves.
2. Repository Pattern
Every database table has a dedicated repository class. The service layer never touches SQLAlchemy directly.
# service.py — zero SQLAlchemy imports
class VerificationService:
def __init__(self, repo: VerificationRepository, ...):
self.repo = repo
async def approve(self, verification_id: str, admin_id: str):
v = await self.repo.get_by_id(verification_id)
self._validate_transition(v.status, VerificationStatus.APPROVED)
v.status = VerificationStatus.APPROVED
v.reviewed_by = admin_id
await self.repo.save(v)
await self.audit_repo.log(v.id, "APPROVED", admin_id)What this enables:
service.pyis testable without a database- Switching from SQLite to PostgreSQL is a connection string change
- Domain models (
models.py) are plain Python dataclasses — the ORM models (database.py) are separate mapped classes (Anti-Corruption Layer)
3. State Machine
Instead of letting any code set verification.status = anything, all transitions go through a single dictionary:
_TRANSITIONS = {
PENDING: {IN_REVIEW},
IN_REVIEW: {APPROVED, REJECTED},
REJECTED: {PENDING}, # user can resubmit
APPROVED: set(), # terminal
}
def _validate_transition(self, current: Status, target: Status):
if target not in _TRANSITIONS[current]:
raise HTTPException(409, f"Invalid transition: {current} → {target}")If code tries PENDING → APPROVED (skipping review), it raises HTTP 409 immediately. The system is structurally incapable of reaching an invalid state — not just documented to avoid it.
State flow:
PENDING ──► IN_REVIEW ──► APPROVED (terminal)
└───► REJECTED ──► PENDING (user resubmits)4. Optimistic Locking
Every verification record has a version integer. On each state change it increments. Two concurrent admin updates to the same case produce a version mismatch:
async def save_with_version_check(self, v: Verification, expected_version: int):
result = await self.session.execute(
update(VerificationRow)
.where(VerificationRow.id == v.id)
.where(VerificationRow.version == expected_version)
.values(status=v.status, version=expected_version + 1)
)
if result.rowcount == 0:
raise HTTPException(409, "Record was modified by another request. Please refresh and retry.")Why optimistic over pessimistic (SELECT FOR UPDATE):
FOR UPDATEis PostgreSQL-specific — breaks SQLite dev/prod parity- Pessimistic locks hold a DB connection open for seconds during user action — doesn't scale
- Two admins reviewing the same case simultaneously is rare — optimistic costs nothing in the happy path
5. AI Pipeline
When a document is uploaded, a background job runs:
- File validation — MIME type check (PDF, JPEG, PNG, WEBP only), 10 MB limit, SHA-256 hash for integrity
- Document classification (
doc-classifier-v1) — simulates OCR + ML confidence scoring - Confidence score — 0.0–1.0 assigned per document
- Threshold check — ≥ 0.70 → Passed; < 0.70 → Manual review required
- AI suggestion —
ApproveorManual review required, shown to admin alongside confidence bar
In production, steps 2–4 would call Azure Document Intelligence or AWS Textract with a real ML classifier trained on document types.
The AI confidence bar in the detail view shows a 70% threshold marker line, making the pass/fail boundary visually clear. The system records both the AI suggestion and the human decision separately — so when an admin overrides the AI, the divergence is captured in the audit trail.
6. Append-Only Audit Trail
async def log(self, entity_id: str, action: str, actor: str, ...):
entry = AuditEntryRow(
entity_id=entity_id,
action=action,
performed_by=actor,
created_at=datetime.utcnow()
)
self.session.add(entry) # NOT session.merge() — prevents overwrites
await self.session.commit()Using session.add() instead of session.merge() makes overwrites structurally impossible. The audit table is an event log — it only grows, never changes. This is the evidence trail for GDPR compliance audits.
GDPR Compliance Design
Data Classification
Under GDPR Article 9, identity documents (passports, national IDs) qualify as sensitive personal data — they reveal nationality, date of birth, and sometimes health information. Stricter rules apply.
How It's Handled
Data minimisation — extracted_data JSON stores only confidence scores and model metadata, not raw OCR text.
Storage limitation — delete_verification_files() permanently deletes all uploaded files. auto_purge_hours config triggers automatic deletion after N hours.
Right to erasure (Article 17):
# Full deletion path:
1. delete_verification_files(verification_id) # removes files from disk/blob
2. DB cascade delete # removes documents, jobs, audit entries
3. Delete verification recordData residency — allow_cloud_processing config defaults to False. No data leaves the local machine unless explicitly enabled. For Norwegian healthcare: Azure Norway East or on-premise deployment keeps data within EEA (Schrems II).
Access control — JWT Bearer required on all endpoints. Admin endpoints use require_role(["admin"]) FastAPI dependency. Every API call is authenticated before any data is touched.
The Hard Parts — What Was Difficult to Build
1. Token Race Condition on Page Load
The biggest frontend challenge: authenticate() is async. If the user clicks Submit before it resolves, the request has no Authorization header → 401.
Three attempts before the solution:
- Attempt 1:
sessionStoragefallback → stale tokens when backend restarted - Attempt 2: Module-level variable → correct in theory, but Vite HMR reloads reset the variable while React preserved
authReady=true(false "authenticated" state) - Final solution:
window.__msToken— a property onwindowthat survives Vite HMR module reloads but clears on full page reload. Combined withsetAuthReady(true)after the token resolves.
Lesson: Frontend auth state in HMR dev environments is subtler than in production builds. Production doesn't have this problem (no HMR), but dev introduces timing bugs that are hard to reproduce.
2. FastAPI Route Ordering
FastAPI matches routes in registration order. /admin/all (literal) was being matched by /{verification_id} (path parameter) before reaching the admin route → 422 errors on the admin list endpoint.
Fix: Register /admin/all before /{verification_id}. FastAPI evaluates literal segments before parameterised ones when registered first. This is non-obvious FastAPI behaviour.
3. Authenticated File Download
Browsers can't set custom headers on <a href> navigations. A simple link to the download endpoint sends no Authorization header → 401.
Solution: Use fetch() with auth header, receive as Blob, create a temporary object URL with URL.createObjectURL(), open in a new tab. The object URL lives in browser memory and is never exposed to the server. This is the standard pattern for authenticated file downloads in SPAs.
4. SQLite Schema Migrations
SQLAlchemy's create_all() only creates missing tables — it doesn't add columns to existing ones. When version was added to VerificationRow, the existing dev database had the old schema and the app failed with cryptic errors.
Dev fix: Delete and recreate the database file. Production requirement: Alembic migrations — a known gap in V1.
Path to Production Scale
Current Architecture
Browser → Vite proxy → FastAPI (single process) → SQLite file
↓
verification_uploads/ (local disk)Step-by-Step Scale Path
Step 1 — Stateless API (already done) JWT tokens carry all session state. Multiple FastAPI instances behind a load balancer work with zero code changes.
Step 2 — PostgreSQL Connection string change + Alembic migration. Enables concurrent writes from multiple API instances.
Step 3 — Real task queue
Currently _run_document_job() runs inline in the request thread. Under load it blocks HTTP responses. The fix:
API request → save job record → return 202 Accepted
↓
Celery worker picks up job
↓
Runs OCR + AI scoring
↓
Updates job + document recordsThe VerificationJob table already has all required fields (worker_id, retry_count, last_error, started_at, completed_at) — only the infrastructure needs wiring.
Step 4 — Blob storage
storage.py is already an abstraction. Replace the local filesystem implementation with Azure Blob Storage. Files become replicated, encrypted at rest, accessible from any API instance.
Step 5 — Read replicas
verification_audit_log grows unbounded (append-only). Audit queries should hit a read replica. PostgreSQL streaming replication makes this a config change.
Production Readiness Checklist
[ ] Replace inline _run_document_job() with Celery + Redis
[ ] Replace storage.py local filesystem with Azure Blob Storage
[ ] Add HelseID / Azure AD integration (replace demo auth)
[ ] Add PostgreSQL with Alembic migrations (remove SQLite create_all)
[ ] Enable allow_cloud_processing=True only in dedicated EEA regions
[ ] Rotate MEDSCRIBE_SECRET_KEY (current 'dev-secret' is local only)
[ ] Add rate limiting on upload endpoint
[ ] Partition verification_audit_log by month for scale
[ ] Add Alembic migrations for schema evolution
[ ] Self-service GDPR erasure endpoint
[ ] Pagination on all list endpointsWhat to Build in Version 2
High priority:
- Real OCR with Azure Document Intelligence / AWS Textract
- Cross-reference extracted name against submitted
full_name - Alembic database migrations (non-negotiable for production)
- Celery task queue for background jobs
- HelseID / Azure AD role assignment (remove client-requestable
role: admin)
Medium priority:
- Conflict retry UX (auto-refresh on 409, don't just show error)
- Email/in-app notifications on approval/rejection
- Document expiry detection (flag expired IDs)
Nice to have:
- Multi-document verification (photo ID + proof of address)
- Reviewer assignment with workload balancing
- Audit trail export as PDF for regulatory filings
- Duplicate detection via SHA-256 hash across cases
Key Architectural Takeaways
| Decision | Why It Matters | |----------|---------------| | Domain isolation | Verification failures can't crash clinical workflows | | Repository pattern | Service layer has zero DB imports — fully testable | | Explicit state machine | Invalid state transitions are structurally impossible | | Optimistic locking | Concurrent admin edits handled without DB-level locks | | AI as signal only | Human-in-the-loop required by EU AI Act for healthcare | | Append-only audit log | GDPR evidence trail — no overwrites by design | | Abstracted storage | Cloud migration is a single-file change |
This module is a template for any system that needs: compliance + auditability + AI assistance + human oversight. The same patterns apply to financial KYC, legal document review, or any regulated industry where AI assists but humans decide.
Run It Locally
# Clone the repo
git clone https://github.com/asmanasir/MedScribe-AI
# Backend
cd MedScribe-AI
python -m venv .venv
.venv\Scripts\activate # Windows
source .venv/bin/activate # Mac/Linux
pip install -r requirements.txt
$env:PYTHONPATH="src"
uvicorn medscribe.api.app:app --reload --port 8000
# Frontend (separate terminal)
cd frontend
npm install
npm run devOpen http://localhost:3000 → click Verification tab. The app auto-authenticates as DR001 (admin role) on startup.
Full source code and documentation: github.com/asmanasir/MedScribe-AI
Found this helpful?
Leave a comment
Have a question, correction, or just found this helpful? Leave a note below.